
Commit
•
95fcb47
1
Parent(s):
5545230
Upload folder using huggingface_hub
Browse files- README.md +16 -16
- assets/confusion_matrix_GGU.png +0 -0
- assets/confusion_matrix_sentiment.png +0 -0
- assets/loss_plot_GGU.png +0 -0
- assets/loss_plot_sentiment.png +0 -0
- heads/GGU.pth +1 -1
- heads/sentiment.pth +1 -1
- model.py +674 -0
- multi-head-sequence-classification-model-model.pth +1 -1
README.md
CHANGED
|
@@ -7,6 +7,7 @@ tags: []
|
|
| 7 |
base_model: BAAI/bge-m3
|
| 8 |
datasets:
|
| 9 |
- philipp-zettl/GGU-xx
|
|
|
|
| 10 |
metrics:
|
| 11 |
|
| 12 |
- accuracy
|
|
@@ -121,7 +122,6 @@ def train_classifier():
|
|
| 121 |
momentum = 0.9
|
| 122 |
l2_reg = 0.25
|
| 123 |
|
| 124 |
-
num_epochs = 2
|
| 125 |
l2_loss_weight = 0.25
|
| 126 |
|
| 127 |
model_conf = {
|
|
@@ -149,7 +149,7 @@ def train_classifier():
|
|
| 149 |
model_conf=model_conf,
|
| 150 |
optimizer_conf={**optimizer_conf, 'lr': 1e-4},
|
| 151 |
scheduler_conf=scheduler_conf,
|
| 152 |
-
num_epochs=
|
| 153 |
l2_loss_weight=l2_loss_weight,
|
| 154 |
use_lr_scheduler=True,
|
| 155 |
train_run=train_run,
|
|
@@ -167,10 +167,10 @@ def train_classifier():
|
|
| 167 |
}
|
| 168 |
|
| 169 |
trainer.classifier.add_head('sentiment', 3)
|
| 170 |
-
new_model, history = trainer.train(dataset_name='philipp-zettl/
|
| 171 |
metrics = history['metrics']
|
| 172 |
history['loss_plot'] = trainer._plot_history(**metrics)
|
| 173 |
-
res = trainer.eval({'sentiment': sentiment_label_map})
|
| 174 |
history['evaluation'] = res['sentiment']
|
| 175 |
|
| 176 |
total_history['sentiment'] = deepcopy(history)
|
|
@@ -231,20 +231,20 @@ def _eval_model(self, dataloader, label_map, sample_key, label_key):
|
|
| 231 |
For evaluation, we used the following metrics: accuracy, precision, recall, f1-score. You can find a detailed classification report here:
|
| 232 |
|
| 233 |
**GGU:**
|
| 234 |
-
| | index | precision |
|
| 235 |
-
|
| 236 |
-
| 0 | Greeting |
|
| 237 |
-
| 1 | Gratitude |
|
| 238 |
-
| 2 | Other |
|
| 239 |
-
| 3 | macro avg |
|
| 240 |
-
| 4 | weighted avg |
|
| 241 |
|
| 242 |
**sentiment:**
|
| 243 |
| | index | precision | recall | f1-score | support |
|
| 244 |
|---:|:-------------|------------:|---------:|-----------:|----------:|
|
| 245 |
-
| 0 | Positive | 0.
|
| 246 |
-
| 1 | Negative | 0.
|
| 247 |
-
| 2 | Neutral | 0.
|
| 248 |
-
| 3 | macro avg | 0.
|
| 249 |
-
| 4 | weighted avg | 0.
|
| 250 |
|
|
|
|
| 7 |
base_model: BAAI/bge-m3
|
| 8 |
datasets:
|
| 9 |
- philipp-zettl/GGU-xx
|
| 10 |
+
- philipp-zettl/sentiment
|
| 11 |
metrics:
|
| 12 |
|
| 13 |
- accuracy
|
|
|
|
| 122 |
momentum = 0.9
|
| 123 |
l2_reg = 0.25
|
| 124 |
|
|
|
|
| 125 |
l2_loss_weight = 0.25
|
| 126 |
|
| 127 |
model_conf = {
|
|
|
|
| 149 |
model_conf=model_conf,
|
| 150 |
optimizer_conf={**optimizer_conf, 'lr': 1e-4},
|
| 151 |
scheduler_conf=scheduler_conf,
|
| 152 |
+
num_epochs=35,
|
| 153 |
l2_loss_weight=l2_loss_weight,
|
| 154 |
use_lr_scheduler=True,
|
| 155 |
train_run=train_run,
|
|
|
|
| 167 |
}
|
| 168 |
|
| 169 |
trainer.classifier.add_head('sentiment', 3)
|
| 170 |
+
new_model, history = trainer.train(dataset_name='philipp-zettl/sentiment', target_heads=['sentiment'], num_epochs=5, sample_key='text')
|
| 171 |
metrics = history['metrics']
|
| 172 |
history['loss_plot'] = trainer._plot_history(**metrics)
|
| 173 |
+
res = trainer.eval({'sentiment': sentiment_label_map}, sample_key='text')
|
| 174 |
history['evaluation'] = res['sentiment']
|
| 175 |
|
| 176 |
total_history['sentiment'] = deepcopy(history)
|
|
|
|
| 231 |
For evaluation, we used the following metrics: accuracy, precision, recall, f1-score. You can find a detailed classification report here:
|
| 232 |
|
| 233 |
**GGU:**
|
| 234 |
+
| | index | precision | recall | f1-score | support |
|
| 235 |
+
|---:|:-------------|------------:|---------:|-----------:|----------:|
|
| 236 |
+
| 0 | Greeting | 0.861111 | 0.837838 | 0.849315 | 37 |
|
| 237 |
+
| 1 | Gratitude | 0.911765 | 0.885714 | 0.898551 | 35 |
|
| 238 |
+
| 2 | Other | 0.914286 | 0.969697 | 0.941176 | 33 |
|
| 239 |
+
| 3 | macro avg | 0.895721 | 0.89775 | 0.896347 | 105 |
|
| 240 |
+
| 4 | weighted avg | 0.894708 | 0.895238 | 0.894598 | 105 |
|
| 241 |
|
| 242 |
**sentiment:**
|
| 243 |
| | index | precision | recall | f1-score | support |
|
| 244 |
|---:|:-------------|------------:|---------:|-----------:|----------:|
|
| 245 |
+
| 0 | Positive | 0.789794 | 0.848009 | 0.817867 | 12685 |
|
| 246 |
+
| 1 | Negative | 0.793988 | 0.834127 | 0.813563 | 14282 |
|
| 247 |
+
| 2 | Neutral | 0.789069 | 0.690309 | 0.736393 | 13239 |
|
| 248 |
+
| 3 | macro avg | 0.790951 | 0.790815 | 0.789274 | 40206 |
|
| 249 |
+
| 4 | weighted avg | 0.791045 | 0.791151 | 0.78951 | 40206 |
|
| 250 |
|
assets/confusion_matrix_GGU.png
CHANGED

|

|
assets/confusion_matrix_sentiment.png
CHANGED

|

|
assets/loss_plot_GGU.png
CHANGED

|

|
assets/loss_plot_sentiment.png
CHANGED

|
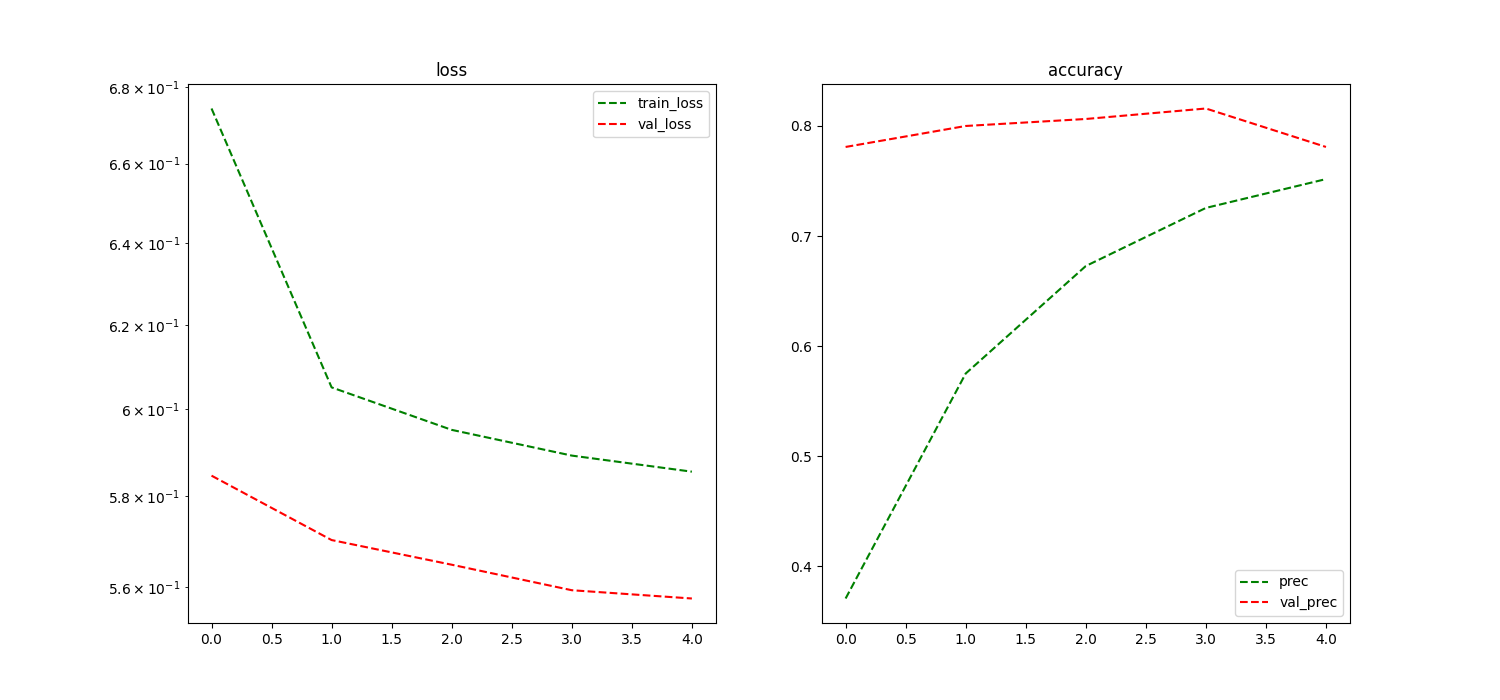
|
heads/GGU.pth
CHANGED
|
@@ -1,3 +1,3 @@
|
|
| 1 |
version https://git-lfs.github.com/spec/v1
|
| 2 |
-
oid sha256:
|
| 3 |
size 7552
|
|
|
|
| 1 |
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:8f0406ada1c1c023a0d2943a98d20f5d0aa1823444dc01fef2c963f1259be4b7
|
| 3 |
size 7552
|
heads/sentiment.pth
CHANGED
|
@@ -1,3 +1,3 @@
|
|
| 1 |
version https://git-lfs.github.com/spec/v1
|
| 2 |
-
oid sha256:
|
| 3 |
size 7652
|
|
|
|
| 1 |
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:c484582887addd315ba9670af09ee288cd30ebde2f47c0fdbd5f5b23f5ef2721
|
| 3 |
size 7652
|
model.py
ADDED
|
@@ -0,0 +1,674 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Description: Classification models
|
| 2 |
+
from transformers import AutoModel, AutoTokenizer, BatchEncoding, TrainingArguments, Trainer
|
| 3 |
+
from functools import partial
|
| 4 |
+
from huggingface_hub import snapshot_download
|
| 5 |
+
from huggingface_hub.constants import HF_HUB_CACHE
|
| 6 |
+
from accelerate import Accelerator
|
| 7 |
+
from accelerate.utils import find_executable_batch_size as auto_find_batch_size
|
| 8 |
+
from datasets import load_dataset, Dataset
|
| 9 |
+
from torch.utils.data import DataLoader
|
| 10 |
+
import torch
|
| 11 |
+
import torch.nn as nn
|
| 12 |
+
import torch.optim as optim
|
| 13 |
+
import numpy as np
|
| 14 |
+
import json
|
| 15 |
+
import os
|
| 16 |
+
from tqdm import tqdm
|
| 17 |
+
import pandas as pd
|
| 18 |
+
|
| 19 |
+
import matplotlib.pyplot as plt
|
| 20 |
+
from sklearn.metrics import (
|
| 21 |
+
ConfusionMatrixDisplay,
|
| 22 |
+
accuracy_score,
|
| 23 |
+
classification_report,
|
| 24 |
+
confusion_matrix,
|
| 25 |
+
f1_score,
|
| 26 |
+
recall_score
|
| 27 |
+
)
|
| 28 |
+
|
| 29 |
+
BASE_PATH = os.path.dirname(os.path.abspath(__file__))
|
| 30 |
+
|
| 31 |
+
|
| 32 |
+
class MultiHeadClassification(nn.Module):
|
| 33 |
+
"""
|
| 34 |
+
MultiHeadClassification
|
| 35 |
+
|
| 36 |
+
An easy to use multi-head classification model. It takes a backbone model and a dictionary of head configurations.
|
| 37 |
+
It can be used to train multiple classification tasks at once using a single backbone model.
|
| 38 |
+
|
| 39 |
+
Apart from joint training, it also supports training individual heads separately, providing a simple way to freeze
|
| 40 |
+
and unfreeze heads.
|
| 41 |
+
|
| 42 |
+
Example:
|
| 43 |
+
>>> from transformers import AutoModel, AutoTokenizer
|
| 44 |
+
>>> from torch.optim import AdamW
|
| 45 |
+
>>> import torch
|
| 46 |
+
>>> import time
|
| 47 |
+
>>> import torch.nn as nn
|
| 48 |
+
>>>
|
| 49 |
+
>>> # Manually load backbone model to create model
|
| 50 |
+
>>> backbone = AutoModel.from_pretrained('BAAI/bge-m3')
|
| 51 |
+
>>> model = MultiHeadClassification(backbone, {'binary': 2, 'sentiment': 3, 'something': 4}).to('cuda')
|
| 52 |
+
>>> print(model)
|
| 53 |
+
>>> # Load tokenizer for data preprocessing
|
| 54 |
+
>>> tokenizer = AutoTokenizer.from_pretrained('BAAI/bge-m3')
|
| 55 |
+
>>> # some training data
|
| 56 |
+
>>> inputs = tokenizer("Hello, my dog is cute", return_tensors="pt", padding=True, truncation=True)
|
| 57 |
+
>>> optimizer = AdamW(model.parameters(), lr=5e-4)
|
| 58 |
+
>>> samples = tokenizer(["Hello, my dog is cute", "Hello, my dog is cute", "I like turtles"], return_tensors="pt", padding=True, truncation=True).to('cuda')
|
| 59 |
+
>>> labels = {'binary': torch.tensor([0, 0, 1]), 'sentiment': torch.tensor([0, 1, 2]), 'something': torch.tensor([0, 1, 2])}
|
| 60 |
+
>>> model.freeze_backbone()
|
| 61 |
+
>>> model.train(True)
|
| 62 |
+
>>> for i in range(10):
|
| 63 |
+
... optimizer.zero_grad()
|
| 64 |
+
... outputs = model(samples)
|
| 65 |
+
... loss = sum([nn.CrossEntropyLoss()(outputs[name].cpu(), labels[name]) for name in model.heads.keys()])
|
| 66 |
+
... loss.backward()
|
| 67 |
+
... optimizer.step()
|
| 68 |
+
... print(loss.item())
|
| 69 |
+
... #time.sleep(1)
|
| 70 |
+
... print(model(samples))
|
| 71 |
+
>>> # Save full model
|
| 72 |
+
>>> model.save('model.pth')
|
| 73 |
+
>>> # Save head only
|
| 74 |
+
>>> model.save_head('binary', 'binary.pth')
|
| 75 |
+
>>> # Load full model
|
| 76 |
+
>>> model = MultiHeadClassification(backbone, {}).to('cuda')
|
| 77 |
+
>>> model.load('model.pth')
|
| 78 |
+
>>> # Load head only
|
| 79 |
+
>>> model = MultiHeadClassification(backbone, {}).to('cuda')
|
| 80 |
+
>>> model.load_head('binary', 'binary.pth')
|
| 81 |
+
>>> # Adding new head
|
| 82 |
+
>>> model.add_head('new_head', 3)
|
| 83 |
+
>>> print(model)
|
| 84 |
+
>>> # extend dataset with data for new head
|
| 85 |
+
>>> labels['new_head'] = torch.tensor([0, 1, 2])
|
| 86 |
+
>>> # Freeze all heads and backbone
|
| 87 |
+
>>> model.freeze_all()
|
| 88 |
+
>>> # Only unfreeze new head
|
| 89 |
+
>>> model.unfreeze_head('new_head')
|
| 90 |
+
>>> model.train(True)
|
| 91 |
+
>>> for i in range(10):
|
| 92 |
+
... optimizer.zero_grad()
|
| 93 |
+
... outputs = model(samples)
|
| 94 |
+
... loss = sum([nn.CrossEntropyLoss()(outputs[name].cpu(), labels[name]) for name in model.heads.keys()])
|
| 95 |
+
... loss.backward()
|
| 96 |
+
... optimizer.step()
|
| 97 |
+
... print(loss.item())
|
| 98 |
+
>>> print(model(samples))
|
| 99 |
+
|
| 100 |
+
Args:
|
| 101 |
+
backbone (transformers.PreTrainedModel): A pretrained transformer model
|
| 102 |
+
head_config (dict): A dictionary with head configurations. The key is the head name and the value is the number
|
| 103 |
+
of classes for that head.
|
| 104 |
+
"""
|
| 105 |
+
def __init__(self, backbone, head_config, dropout=0.1, l2_reg=0.01):
|
| 106 |
+
super().__init__()
|
| 107 |
+
self.backbone = backbone
|
| 108 |
+
self.num_heads = len(head_config)
|
| 109 |
+
self.heads = nn.ModuleDict({
|
| 110 |
+
name: nn.Linear(backbone.config.hidden_size, num_classes)
|
| 111 |
+
for name, num_classes in head_config.items()
|
| 112 |
+
})
|
| 113 |
+
self.do = nn.Dropout(dropout)
|
| 114 |
+
self.l2_reg = l2_reg
|
| 115 |
+
self.device = 'cpu'
|
| 116 |
+
self.torch_dtype = torch.float16
|
| 117 |
+
self.head_config = head_config
|
| 118 |
+
|
| 119 |
+
def forward(self, x, head_names=None) -> dict:
|
| 120 |
+
"""
|
| 121 |
+
Forward pass of the model.
|
| 122 |
+
|
| 123 |
+
Requires tokenizer output as input. The input should be a dictionary with keys 'input_ids', 'attention_mask'.
|
| 124 |
+
|
| 125 |
+
Args:
|
| 126 |
+
x (dict): Tokenizer output
|
| 127 |
+
head_names (list): (optional) List of head names to return logits for. If None, returns logits for all heads.
|
| 128 |
+
|
| 129 |
+
Returns:
|
| 130 |
+
dict: A dictionary with head names as keys and logits as values
|
| 131 |
+
"""
|
| 132 |
+
x = self.backbone(**x, return_dict=True, output_hidden_states=True).last_hidden_state[:, 0, :]
|
| 133 |
+
x = self.do(x)
|
| 134 |
+
if head_names is None:
|
| 135 |
+
return {name: head(x) for name, head in self.heads.items()}
|
| 136 |
+
return {name: head(x) for name, head in self.heads.items() if name in head_names}
|
| 137 |
+
|
| 138 |
+
def get_l2_loss(self):
|
| 139 |
+
"""
|
| 140 |
+
Getter for L2 regularization loss
|
| 141 |
+
|
| 142 |
+
Returns:
|
| 143 |
+
torch.Tensor: L2 regularization loss
|
| 144 |
+
"""
|
| 145 |
+
l2_loss = torch.tensor(0.).to(self.device)
|
| 146 |
+
for param in self.parameters():
|
| 147 |
+
if param.requires_grad:
|
| 148 |
+
l2_loss += torch.norm(param, 2)
|
| 149 |
+
return (self.l2_reg * l2_loss).to(self.device)
|
| 150 |
+
|
| 151 |
+
def to(self, *args, **kwargs):
|
| 152 |
+
super().to(*args, **kwargs)
|
| 153 |
+
if isinstance(args[0], torch.dtype):
|
| 154 |
+
self.torch_dtype = args[0]
|
| 155 |
+
elif isinstance(args[0], str):
|
| 156 |
+
self.device = args[0]
|
| 157 |
+
return self
|
| 158 |
+
|
| 159 |
+
def load_head(self, head_name, path):
|
| 160 |
+
"""
|
| 161 |
+
Load head from a file
|
| 162 |
+
|
| 163 |
+
Args:
|
| 164 |
+
head_name (str): Name of the head
|
| 165 |
+
path (str): Path to the file
|
| 166 |
+
|
| 167 |
+
Returns:
|
| 168 |
+
None
|
| 169 |
+
"""
|
| 170 |
+
model = torch.load(path)
|
| 171 |
+
if head_name in self.heads:
|
| 172 |
+
num_classes = model['weight'].shape[0]
|
| 173 |
+
self.heads[head_name].load_state_dict(model)
|
| 174 |
+
self.to(self.torch_dtype).to(self.device)
|
| 175 |
+
self.head_config[head_name] = num_classes
|
| 176 |
+
return
|
| 177 |
+
|
| 178 |
+
assert model['weight'].shape[1] == self.backbone.config.hidden_size
|
| 179 |
+
num_classes = model['weight'].shape[0]
|
| 180 |
+
self.heads[head_name] = nn.Linear(self.backbone.config.hidden_size, num_classes)
|
| 181 |
+
self.heads[head_name].load_state_dict(model)
|
| 182 |
+
self.head_config[head_name] = num_classes
|
| 183 |
+
|
| 184 |
+
self.to(self.torch_dtype).to(self.device)
|
| 185 |
+
|
| 186 |
+
def save_head(self, head_name, path):
|
| 187 |
+
"""
|
| 188 |
+
Save head to a file
|
| 189 |
+
|
| 190 |
+
Args:
|
| 191 |
+
head_name (str): Name of the head
|
| 192 |
+
path (str): Path to the file
|
| 193 |
+
"""
|
| 194 |
+
torch.save(self.heads[head_name].state_dict(), path)
|
| 195 |
+
|
| 196 |
+
def save(self, path):
|
| 197 |
+
"""
|
| 198 |
+
Save the full model to a file
|
| 199 |
+
|
| 200 |
+
Args:
|
| 201 |
+
path (str): Path to the file
|
| 202 |
+
"""
|
| 203 |
+
torch.save(self.state_dict(), path)
|
| 204 |
+
|
| 205 |
+
def load(self, path):
|
| 206 |
+
"""
|
| 207 |
+
Load the full model from a file
|
| 208 |
+
|
| 209 |
+
Args:
|
| 210 |
+
path (str): Path to the file
|
| 211 |
+
"""
|
| 212 |
+
self.load_state_dict(torch.load(path))
|
| 213 |
+
self.to(self.torch_dtype).to(self.device)
|
| 214 |
+
|
| 215 |
+
def save_backbone(self, path):
|
| 216 |
+
"""
|
| 217 |
+
Save the backbone to a file
|
| 218 |
+
|
| 219 |
+
Args:
|
| 220 |
+
path (str): Path to the file
|
| 221 |
+
"""
|
| 222 |
+
self.backbone.save_pretrained(path)
|
| 223 |
+
|
| 224 |
+
def load_backbone(self, path):
|
| 225 |
+
"""
|
| 226 |
+
Load the backbone from a file
|
| 227 |
+
|
| 228 |
+
Args:
|
| 229 |
+
path (str): Path to the file
|
| 230 |
+
"""
|
| 231 |
+
self.backbone = AutoModel.from_pretrained(path)
|
| 232 |
+
self.to(self.torch_dtype).to(self.device)
|
| 233 |
+
|
| 234 |
+
def freeze_backbone(self):
|
| 235 |
+
""" Freeze the backbone """
|
| 236 |
+
for param in self.backbone.parameters():
|
| 237 |
+
param.requires_grad = False
|
| 238 |
+
|
| 239 |
+
def unfreeze_backbone(self):
|
| 240 |
+
""" Unfreeze the backbone """
|
| 241 |
+
for param in self.backbone.parameters():
|
| 242 |
+
param.requires_grad = True
|
| 243 |
+
|
| 244 |
+
def freeze_head(self, head_name):
|
| 245 |
+
"""
|
| 246 |
+
Freeze a head by name
|
| 247 |
+
|
| 248 |
+
Args:
|
| 249 |
+
head_name (str): Name of the head
|
| 250 |
+
"""
|
| 251 |
+
for param in self.heads[head_name].parameters():
|
| 252 |
+
param.requires_grad = False
|
| 253 |
+
|
| 254 |
+
def unfreeze_head(self, head_name):
|
| 255 |
+
"""
|
| 256 |
+
Unfreeze a head by name
|
| 257 |
+
|
| 258 |
+
Args:
|
| 259 |
+
head_name (str): Name of the head
|
| 260 |
+
"""
|
| 261 |
+
for param in self.heads[head_name].parameters():
|
| 262 |
+
param.requires_grad = True
|
| 263 |
+
|
| 264 |
+
def freeze_all_heads(self):
|
| 265 |
+
""" Freeze all heads """
|
| 266 |
+
for head_name in self.heads.keys():
|
| 267 |
+
self.freeze_head(head_name)
|
| 268 |
+
|
| 269 |
+
def unfreeze_all_heads(self):
|
| 270 |
+
""" Unfreeze all heads """
|
| 271 |
+
for head_name in self.heads.keys():
|
| 272 |
+
self.unfreeze_head(head_name)
|
| 273 |
+
|
| 274 |
+
def freeze_all(self):
|
| 275 |
+
""" Freeze all """
|
| 276 |
+
self.freeze_backbone()
|
| 277 |
+
self.freeze_all_heads()
|
| 278 |
+
|
| 279 |
+
def unfreeze_all(self):
|
| 280 |
+
""" Unfreeze all """
|
| 281 |
+
self.unfreeze_backbone()
|
| 282 |
+
self.unfreeze_all_heads()
|
| 283 |
+
|
| 284 |
+
def add_head(self, head_name, num_classes):
|
| 285 |
+
"""
|
| 286 |
+
Add a new head to the model
|
| 287 |
+
|
| 288 |
+
Args:
|
| 289 |
+
head_name (str): Name of the head
|
| 290 |
+
num_classes (int): Number of classes for the head
|
| 291 |
+
"""
|
| 292 |
+
self.heads[head_name] = nn.Linear(self.backbone.config.hidden_size, num_classes)
|
| 293 |
+
self.heads[head_name].to(self.torch_dtype).to(self.device)
|
| 294 |
+
self.head_config[head_name] = num_classes
|
| 295 |
+
|
| 296 |
+
def remove_head(self, head_name):
|
| 297 |
+
"""
|
| 298 |
+
Remove a head from the model
|
| 299 |
+
"""
|
| 300 |
+
if head_name not in self.heads:
|
| 301 |
+
raise ValueError(f'Head {head_name} not found')
|
| 302 |
+
del self.heads[head_name]
|
| 303 |
+
del self.head_config[head_name]
|
| 304 |
+
|
| 305 |
+
@classmethod
|
| 306 |
+
def from_pretrained(cls, model_name, head_config=None, dropout=0.1, l2_reg=0.01):
|
| 307 |
+
"""
|
| 308 |
+
Load a pretrained model from Huggingface model hub
|
| 309 |
+
|
| 310 |
+
Args:
|
| 311 |
+
model_name (str): Name of the model
|
| 312 |
+
head_config (dict): Head configuration
|
| 313 |
+
dropout (float): Dropout rate
|
| 314 |
+
l2_reg (float): L2 regularization rate
|
| 315 |
+
"""
|
| 316 |
+
if head_config is None:
|
| 317 |
+
head_config = {}
|
| 318 |
+
# check if model exists locally
|
| 319 |
+
hf_cache_dir = HF_HUB_CACHE
|
| 320 |
+
model_path = os.path.join(hf_cache_dir, model_name)
|
| 321 |
+
if os.path.exists(model_path):
|
| 322 |
+
return cls._from_directory(model_path, head_config, dropout, l2_reg)
|
| 323 |
+
|
| 324 |
+
model_path = snapshot_download(repo_id=model_name, cache_dir=hf_cache_dir)
|
| 325 |
+
return cls._from_directory(model_path, head_config, dropout, l2_reg)
|
| 326 |
+
|
| 327 |
+
@classmethod
|
| 328 |
+
def _from_directory(cls, model_path, head_config, dropout=0.1, l2_reg=0.01):
|
| 329 |
+
"""
|
| 330 |
+
Load a model from a directory
|
| 331 |
+
|
| 332 |
+
Args:
|
| 333 |
+
model_path (str): Path to the model directory
|
| 334 |
+
head_config (dict): Head configuration
|
| 335 |
+
dropout (float): Dropout rate
|
| 336 |
+
l2_reg (float): L2 regularization rate
|
| 337 |
+
"""
|
| 338 |
+
backbone = AutoModel.from_pretrained(os.path.join(model_path, 'pretrained/backbone.pth'))
|
| 339 |
+
instance = cls(backbone, head_config, dropout, l2_reg)
|
| 340 |
+
instance.load(os.path.join(model_path, 'pretrained/model.pth'))
|
| 341 |
+
instance.head_config = {k: v. instance.heads}
|
| 342 |
+
return instance
|
| 343 |
+
|
| 344 |
+
class MultiHeadClassificationTrainer:
|
| 345 |
+
def __init__(self, **kwargs):
|
| 346 |
+
self.model_conf = kwargs.get('model_conf', {})
|
| 347 |
+
self.optimizer_conf = kwargs.get('optimizer_conf', {})
|
| 348 |
+
self.scheduler_conf = kwargs.get('scheduler_conf', {})
|
| 349 |
+
self.dropout = kwargs.get('dropout', 0.1)
|
| 350 |
+
self.l2_loss_weight = kwargs.get('l2_loss_weight', 0.01)
|
| 351 |
+
self.num_epochs = kwargs.get('num_epochs', 100)
|
| 352 |
+
self.device = kwargs.get('device', 'cuda')
|
| 353 |
+
self.train_run = kwargs.get('train_run', 0)
|
| 354 |
+
self.name_prefix = kwargs.get('name_prefix', 'multihead-classification')
|
| 355 |
+
self.use_lr_scheduler = kwargs.get('use_lr_scheduler', True)
|
| 356 |
+
self.gradient_accumulation_steps = kwargs.get('gradient_accumulation_steps', 1)
|
| 357 |
+
self.batch_size = kwargs.get('batch_size', 4)
|
| 358 |
+
self.train_test_split = kwargs.get('train_test_split', 0.2)
|
| 359 |
+
self.load_best = kwargs.get('load_best', True)
|
| 360 |
+
self.auto_find_batch_size = kwargs.get('auto_find_batch_size', False)
|
| 361 |
+
self.test_data = None
|
| 362 |
+
self.accelerator = Accelerator()
|
| 363 |
+
|
| 364 |
+
self.classifier = MultiHeadClassification(
|
| 365 |
+
**self.model_conf
|
| 366 |
+
).to(torch.float16)
|
| 367 |
+
self.classifier.freeze_backbone()
|
| 368 |
+
self.tokenizer = AutoTokenizer.from_pretrained(self.model_conf.get('tokenizer', self.classifier.backbone.name_or_path), model_max_length=128)
|
| 369 |
+
|
| 370 |
+
def _batch_data(self, batch_size, data):
|
| 371 |
+
return DataLoader(data, shuffle=True, batch_size=batch_size)
|
| 372 |
+
|
| 373 |
+
def train(self, dataset_name: str = None, train_data: DataLoader = None, val_data: DataLoader = None, lr: float = None, num_epochs: int = None, target_heads: list[str] = None, batch_size: int = 4, sample_key=None, label_key=None):
|
| 374 |
+
has_dataset = train_data is not None
|
| 375 |
+
assert (dataset_name is not None and not has_dataset) or (has_dataset and dataset_name is None), 'Must provide either dataset or dataset_name'
|
| 376 |
+
if dataset_name is not None:
|
| 377 |
+
assert target_heads is not None, 'target_heads must be provided when using dataset_name'
|
| 378 |
+
|
| 379 |
+
if sample_key is None:
|
| 380 |
+
sample_key = 'sample'
|
| 381 |
+
if label_key is None:
|
| 382 |
+
label_key = 'label'
|
| 383 |
+
|
| 384 |
+
self.accelerator.free_memory()
|
| 385 |
+
self.classifier = self.accelerator.prepare(self.classifier)
|
| 386 |
+
|
| 387 |
+
if dataset_name is not None:
|
| 388 |
+
dataset = load_dataset(dataset_name)['train'].train_test_split(test_size=self.train_test_split)
|
| 389 |
+
train_data = dataset['train']
|
| 390 |
+
val_data = dataset['test'].train_test_split(test_size=0.5)
|
| 391 |
+
self.test_data = val_data['test']
|
| 392 |
+
val_data = val_data['train']
|
| 393 |
+
|
| 394 |
+
if batch_size is not None:
|
| 395 |
+
self.batch_size = batch_size
|
| 396 |
+
|
| 397 |
+
if isinstance(train_data, Dataset):
|
| 398 |
+
sample = next(iter(train_data))
|
| 399 |
+
print('Tokenizing dataset...', sample, type(sample))
|
| 400 |
+
is_string_dataset = isinstance(sample[0], str) if not isinstance(sample, dict) else isinstance(sample[sample_key], str)
|
| 401 |
+
|
| 402 |
+
if is_string_dataset:
|
| 403 |
+
if isinstance(sample, list):
|
| 404 |
+
train_data = train_data.map(lambda x: self.tokenizer([x[0]] if isinstance(x[0], str) else x[0], return_tensors="pt", padding=True, truncation=True), batched=True)
|
| 405 |
+
val_data = val_data.map(lambda x: self.tokenizer([x[0]] if isinstance(x[0], str) else x[0], return_tensors="pt", padding=True, truncation=True), batched=True)
|
| 406 |
+
elif isinstance(sample, dict):
|
| 407 |
+
assert sample_key in sample and label_key in sample, 'Invalid dataset format'
|
| 408 |
+
train_data = train_data.map(lambda x: self.tokenizer([x[sample_key]] if isinstance(x[sample_key], str) else x[sample_key], return_tensors="pt", padding=True, truncation=True), batched=True)
|
| 409 |
+
val_data = val_data.map(lambda x: self.tokenizer([x[sample_key]] if isinstance(x[sample_key], str) else x[sample_key], return_tensors="pt", padding=True, truncation=True), batched=True)
|
| 410 |
+
else:
|
| 411 |
+
raise ValueError('Invalid dataset format')
|
| 412 |
+
|
| 413 |
+
create_train_data = partial(self._batch_data, data=train_data)
|
| 414 |
+
create_val_data = partial(self._batch_data, data=val_data)
|
| 415 |
+
|
| 416 |
+
if self.auto_find_batch_size:
|
| 417 |
+
train_data = auto_find_batch_size(create_train_data)()
|
| 418 |
+
val_data = auto_find_batch_size(create_val_data)()
|
| 419 |
+
else:
|
| 420 |
+
train_data = create_train_data(self.batch_size)
|
| 421 |
+
val_data = create_val_data(self.batch_size)
|
| 422 |
+
# otherwise, assume it's already tokenized
|
| 423 |
+
else:
|
| 424 |
+
assert train_data is not None and val_data is not None, 'train_data and val_data must be provided'
|
| 425 |
+
assert isinstance(train_data, DataLoader) and isinstance(val_data, DataLoader), 'train_data and val_data must be DataLoader instances'
|
| 426 |
+
|
| 427 |
+
optimizer_name = self.optimizer_conf.pop('optimizer', 'sgd')
|
| 428 |
+
loss_name = self.optimizer_conf.pop('loss', 'crossentropy')
|
| 429 |
+
if lr:
|
| 430 |
+
self.optimizer_conf['lr'] = lr
|
| 431 |
+
if num_epochs:
|
| 432 |
+
self.num_epochs = num_epochs
|
| 433 |
+
|
| 434 |
+
self.classifier.unfreeze_all()
|
| 435 |
+
# freeze backbone
|
| 436 |
+
print('Freezing backbone')
|
| 437 |
+
self.classifier.freeze_backbone()
|
| 438 |
+
# freeze all heads that are not in the training data
|
| 439 |
+
|
| 440 |
+
if target_heads is None:
|
| 441 |
+
sample = next(iter(train_data))
|
| 442 |
+
if isinstance(sample, dict):
|
| 443 |
+
train_heads = list(sample[label_key].keys())
|
| 444 |
+
elif isinstance(sample, list):
|
| 445 |
+
train_heads = list(sample[1].keys())
|
| 446 |
+
else:
|
| 447 |
+
raise ValueError('Invalid dataset format')
|
| 448 |
+
else:
|
| 449 |
+
train_heads = target_heads
|
| 450 |
+
|
| 451 |
+
for head_name in self.classifier.heads.keys():
|
| 452 |
+
if head_name not in train_heads:
|
| 453 |
+
print(f'Freezing head {head_name}')
|
| 454 |
+
self.classifier.freeze_head(head_name)
|
| 455 |
+
|
| 456 |
+
self.classifier.to(self.device)
|
| 457 |
+
self.classifier.train(True)
|
| 458 |
+
loss_func = {'crossentropy': nn.CrossEntropyLoss, 'bce': nn.BCELoss}.get(loss_name, nn.CrossEntropyLoss)
|
| 459 |
+
optimizer_class = {'sgd': optim.SGD, 'adam': optim.Adam}.get(optimizer_name, optim.SGD)
|
| 460 |
+
optimizer = optimizer_class(self.classifier.parameters(), **self.optimizer_conf)
|
| 461 |
+
|
| 462 |
+
scheduler = None
|
| 463 |
+
if self.use_lr_scheduler:
|
| 464 |
+
scheduler_class = {
|
| 465 |
+
'plateau': optim.lr_scheduler.ReduceLROnPlateau,
|
| 466 |
+
'step': optim.lr_scheduler.StepLR,
|
| 467 |
+
}.get(self.scheduler_conf.get('scheduler'), optim.lr_scheduler.ReduceLROnPlateau)
|
| 468 |
+
scheduler = scheduler_class(optimizer, 'min', **self.scheduler_conf)
|
| 469 |
+
|
| 470 |
+
history = self._train(loss_func(), optimizer, scheduler, self.accelerator.prepare(train_data), self.accelerator.prepare(val_data), train_heads, sample_key, label_key)
|
| 471 |
+
if self.load_best:
|
| 472 |
+
self.classifier.load(os.path.join(BASE_PATH, f'../train_runs/{self.name_prefix}-run-{self.train_run-1}-best-model.pth'))
|
| 473 |
+
return self.classifier, history
|
| 474 |
+
|
| 475 |
+
def _train(self, criterion, optimizer, scheduler, dataloader, val_dataloader, head_names, sample_key, label_key):
|
| 476 |
+
average_acc = 0
|
| 477 |
+
losses = []
|
| 478 |
+
precisions = []
|
| 479 |
+
best_prec = 0.0
|
| 480 |
+
|
| 481 |
+
val_losses = []
|
| 482 |
+
val_accs = []
|
| 483 |
+
avg_val_acc = 0.0
|
| 484 |
+
|
| 485 |
+
patience = 50
|
| 486 |
+
reset_patience = 25
|
| 487 |
+
patience_reset_counter = 0
|
| 488 |
+
patience_counter = 0
|
| 489 |
+
current_max = 0
|
| 490 |
+
total_max = 0
|
| 491 |
+
num_samples = len(dataloader)
|
| 492 |
+
pbar = tqdm(total=self.num_epochs * num_samples, desc='Training model...')
|
| 493 |
+
for epoch in range(self.num_epochs):
|
| 494 |
+
self.classifier.train() # Set the model to training mode
|
| 495 |
+
running_loss = 0.0
|
| 496 |
+
all_preds = {name: [] for name in head_names}
|
| 497 |
+
all_labels = {name: [] for name in head_names}
|
| 498 |
+
|
| 499 |
+
for step, sample in enumerate(dataloader):
|
| 500 |
+
labels = {name: sample[label_key] for name in head_names}
|
| 501 |
+
embeddings = BatchEncoding({k: torch.stack(v, dim=1).to(self.device) for k, v in sample.items() if k not in [label_key, sample_key]}).to(self.device)
|
| 502 |
+
outputs = self.classifier(embeddings, head_names=head_names) # Forward pass
|
| 503 |
+
loss = sum([criterion(outputs[name].to(self.device), labels[name].to(self.device)) for name in labels.keys()])
|
| 504 |
+
loss += self.l2_loss_weight * self.classifier.get_l2_loss().to(self.device)
|
| 505 |
+
running_loss += loss.item()
|
| 506 |
+
loss.backward() # Backward pass
|
| 507 |
+
if (step + 1) % self.gradient_accumulation_steps == 0:
|
| 508 |
+
optimizer.step() # Update model parameters
|
| 509 |
+
optimizer.zero_grad() # Zero the parameter gradients
|
| 510 |
+
# Store predictions and labels for precision calculation
|
| 511 |
+
for name in labels.keys():
|
| 512 |
+
preds = outputs[name][0].argmax().item()
|
| 513 |
+
all_labels[name].append(labels[name][0].cpu().numpy())
|
| 514 |
+
all_preds[name].append(preds)
|
| 515 |
+
|
| 516 |
+
pbar.update(1)
|
| 517 |
+
# clear memory
|
| 518 |
+
torch.cuda.empty_cache()
|
| 519 |
+
|
| 520 |
+
epoch_loss = running_loss / num_samples
|
| 521 |
+
if scheduler:
|
| 522 |
+
scheduler.step(epoch_loss)
|
| 523 |
+
|
| 524 |
+
average_acc += np.mean([np.mean(np.abs(np.array(all_labels[name]) - np.array(all_preds[name])) == 0) for name in head_names])
|
| 525 |
+
average_acc /= 2.0
|
| 526 |
+
if val_dataloader:
|
| 527 |
+
val_loss, val_acc = self.validate(self.classifier, criterion, val_dataloader, head_names, sample_key, label_key)
|
| 528 |
+
avg_val_acc += val_acc.item()
|
| 529 |
+
avg_val_acc /= 2.0
|
| 530 |
+
val_losses.append(val_loss)
|
| 531 |
+
val_accs.append(val_acc)
|
| 532 |
+
losses.append(epoch_loss)
|
| 533 |
+
precisions.append(average_acc)
|
| 534 |
+
if avg_val_acc > current_max:
|
| 535 |
+
current_max = avg_val_acc
|
| 536 |
+
self.classifier.save(os.path.join(BASE_PATH, f'../train_runs/{self.name_prefix}-run-{self.train_run}-best-model.pth'))
|
| 537 |
+
best_prec = max(average_acc, best_prec)
|
| 538 |
+
#print(f"Epoch {epoch+1}/{num_epochs} (LR: {scheduler.get_last_lr()[0]:.4e}), Loss: {epoch_loss:.4f}, Precision: {l:.4f}")
|
| 539 |
+
pbar_data = {
|
| 540 |
+
'epoch': epoch + 1,
|
| 541 |
+
'loss': epoch_loss,
|
| 542 |
+
'avg_acc': average_acc,
|
| 543 |
+
'acc_max': best_prec
|
| 544 |
+
}
|
| 545 |
+
if scheduler:
|
| 546 |
+
pbar_data['lr'] = scheduler.get_last_lr()[0]
|
| 547 |
+
if val_dataloader:
|
| 548 |
+
pbar_data['val_loss'] = val_loss
|
| 549 |
+
pbar_data['val_acc'] = val_acc
|
| 550 |
+
pbar_data['avg_val_acc'] = avg_val_acc
|
| 551 |
+
pbar.set_postfix(pbar_data)
|
| 552 |
+
# clear memory
|
| 553 |
+
torch.cuda.empty_cache()
|
| 554 |
+
|
| 555 |
+
pbar.close()
|
| 556 |
+
param_dict = {
|
| 557 |
+
'dropout': self.dropout,
|
| 558 |
+
'model_conf': {k:v for k, v in self.model_conf.items() if k not in ['tokenizer', 'backbone']},
|
| 559 |
+
'optimizer_conf': self.optimizer_conf,
|
| 560 |
+
'scheduler_conf': self.scheduler_conf,
|
| 561 |
+
'l2_loss_weight': self.l2_loss_weight,
|
| 562 |
+
'num_epochs': self.num_epochs,
|
| 563 |
+
'device': self.device,
|
| 564 |
+
'train_run': self.train_run,
|
| 565 |
+
'name_prefix': self.name_prefix,
|
| 566 |
+
'use_lr_scheduler': self.use_lr_scheduler,
|
| 567 |
+
'metrics': {
|
| 568 |
+
'loss': losses,
|
| 569 |
+
'val_loss': val_losses,
|
| 570 |
+
'precision': precisions,
|
| 571 |
+
'val_precision': val_accs
|
| 572 |
+
}
|
| 573 |
+
}
|
| 574 |
+
with open(os.path.join(BASE_PATH, f'../train_runs/{self.name_prefix}-train-run-{self.train_run}.json'), 'w') as f:
|
| 575 |
+
json.dump(param_dict, f)
|
| 576 |
+
print("Training complete!")
|
| 577 |
+
self.train_run += 1
|
| 578 |
+
|
| 579 |
+
return param_dict
|
| 580 |
+
|
| 581 |
+
def _plot_history(self, loss, val_loss, precision, val_precision):
|
| 582 |
+
fig = plt.figure(figsize=(15,7))
|
| 583 |
+
ax = plt.subplot(1,2, 1)
|
| 584 |
+
ax.set_title('loss')
|
| 585 |
+
plt.plot(range(len(loss)), loss, 'g--', label='train_loss')
|
| 586 |
+
plt.plot(range(len(loss)), val_loss, 'r--', label='val_loss')
|
| 587 |
+
plt.yscale('log')
|
| 588 |
+
plt.legend()
|
| 589 |
+
ax = plt.subplot(1,2, 2)
|
| 590 |
+
ax.set_title('accuracy')
|
| 591 |
+
plt.plot(range(len(precision)), precision, 'g--', label='prec')
|
| 592 |
+
plt.plot(range(len(precision)), val_precision, 'r--',label='val_prec')
|
| 593 |
+
plt.legend()
|
| 594 |
+
return fig
|
| 595 |
+
|
| 596 |
+
def validate(self, model, criterion, dataloader, head_names=None, sample_key='sample', label_key='label'):
|
| 597 |
+
running_loss = 0
|
| 598 |
+
num_samples = len(dataloader)
|
| 599 |
+
if head_names is None:
|
| 600 |
+
sample = next(iter(dataloader))[1]
|
| 601 |
+
head_names = list(sample.keys())
|
| 602 |
+
|
| 603 |
+
all_labels = {name: [] for name in head_names}
|
| 604 |
+
all_preds = {name: [] for name in head_names}
|
| 605 |
+
|
| 606 |
+
num_labels = {name: model.heads[name].out_features for name in head_names}
|
| 607 |
+
|
| 608 |
+
model.train(False)
|
| 609 |
+
for sample in dataloader:
|
| 610 |
+
labels = {name: sample[label_key] for name in head_names}
|
| 611 |
+
embeddings = BatchEncoding({k: torch.stack(v, dim=1).to(self.device) for k, v in sample.items() if k not in [label_key, sample_key]})
|
| 612 |
+
outputs = model(embeddings) # Forward pass
|
| 613 |
+
loss = sum([criterion(outputs[name].to(self.device), labels[name].to(self.device)) for name in head_names])
|
| 614 |
+
loss += self.l2_loss_weight * model.get_l2_loss().to(self.device)
|
| 615 |
+
running_loss += loss.item()
|
| 616 |
+
# Store predictions and labels for precision calculation
|
| 617 |
+
for name in head_names:
|
| 618 |
+
preds = outputs[name][0].argmax().item()
|
| 619 |
+
all_labels[name].append(labels[name][0].cpu().numpy())
|
| 620 |
+
all_preds[name].append(preds)
|
| 621 |
+
torch.cuda.empty_cache()
|
| 622 |
+
return running_loss / num_samples, np.mean([np.mean(np.abs(np.array(all_labels[name]) - np.array(all_preds[name])) == 0) for name in head_names])
|
| 623 |
+
|
| 624 |
+
def eval(self, label_map, test_set=None, sample_key='sample', label_key='label'):
|
| 625 |
+
if test_set is None:
|
| 626 |
+
assert self.test_data is not None, 'No test data provided'
|
| 627 |
+
test_set = self.test_data
|
| 628 |
+
sample = next(iter(test_set))
|
| 629 |
+
is_string_dataset = isinstance(sample[0], str) if not isinstance(sample, dict) else isinstance(sample[sample_key], str)
|
| 630 |
+
|
| 631 |
+
if is_string_dataset:
|
| 632 |
+
if isinstance(sample, list):
|
| 633 |
+
test_set = test_set.map(lambda x: self.tokenizer([x[0]] if isinstance(x[0], str) else x[0], return_tensors="pt", padding=True, truncation=True), batched=True)
|
| 634 |
+
elif isinstance(sample, dict):
|
| 635 |
+
assert sample_key in sample and label_key in sample, 'Invalid dataset format'
|
| 636 |
+
test_set = test_set.map(lambda x: self.tokenizer([x[sample_key]] if isinstance(x[sample_key], str) else x[sample_key], return_tensors="pt", padding=True, truncation=True), batched=True)
|
| 637 |
+
else:
|
| 638 |
+
raise ValueError('Invalid dataset format')
|
| 639 |
+
|
| 640 |
+
test_set = DataLoader(test_set, shuffle=True, batch_size=self.batch_size)
|
| 641 |
+
self.classifier.to(self.device)
|
| 642 |
+
return self._eval_model(test_set, label_map, sample_key, label_key)
|
| 643 |
+
|
| 644 |
+
def _eval_model(self, dataloader, label_map, sample_key, label_key):
|
| 645 |
+
self.classifier.train(False)
|
| 646 |
+
eval_heads = list(label_map.keys())
|
| 647 |
+
y_pred = {h: [] for h in eval_heads}
|
| 648 |
+
y_test = {h: [] for h in eval_heads}
|
| 649 |
+
for sample in tqdm(dataloader, total=len(dataloader), desc='Evaluating model...'):
|
| 650 |
+
labels = {name: sample[label_key] for name in eval_heads}
|
| 651 |
+
embeddings = BatchEncoding({k: torch.stack(v, dim=1).to(self.device) for k, v in sample.items() if k not in [label_key, sample_key]})
|
| 652 |
+
output = self.classifier(embeddings.to('cuda'), head_names=eval_heads)
|
| 653 |
+
for head in eval_heads:
|
| 654 |
+
y_pred[head].extend(output[head].argmax(dim=1).cpu())
|
| 655 |
+
y_test[head].extend(labels[head])
|
| 656 |
+
torch.cuda.empty_cache()
|
| 657 |
+
|
| 658 |
+
accuracies = {h: accuracy_score(y_test[h], y_pred[h]) for h in eval_heads}
|
| 659 |
+
f1_scores = {h: f1_score(y_test[h], y_pred[h], average="macro") for h in eval_heads}
|
| 660 |
+
recalls = {h: recall_score(y_test[h], y_pred[h], average='macro') for h in eval_heads}
|
| 661 |
+
|
| 662 |
+
report = {}
|
| 663 |
+
for head in eval_heads:
|
| 664 |
+
cm = confusion_matrix(y_test[head], y_pred[head], labels=list(label_map[head].keys()))
|
| 665 |
+
disp = ConfusionMatrixDisplay(confusion_matrix=cm, display_labels=list(label_map[head].values()))
|
| 666 |
+
clf_report = classification_report(
|
| 667 |
+
y_test[head], y_pred[head], output_dict=True, target_names=list(label_map[head].values())
|
| 668 |
+
)
|
| 669 |
+
del clf_report["accuracy"]
|
| 670 |
+
clf_report = pd.DataFrame(clf_report).T.reset_index()
|
| 671 |
+
report[head] = dict(
|
| 672 |
+
clf_report=clf_report, confusion_matrix=disp, metrics={'accuracy': accuracies[head], 'f1': f1_scores[head], 'recall': recalls[head]}
|
| 673 |
+
)
|
| 674 |
+
return report
|
multi-head-sequence-classification-model-model.pth
CHANGED
|
@@ -1,3 +1,3 @@
|
|
| 1 |
version https://git-lfs.github.com/spec/v1
|
| 2 |
-
oid sha256:
|
| 3 |
size 1135701541
|
|
|
|
| 1 |
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:11a81b327d68a9c64534a68a223337a474abdf1c538eed908add65a2270010e1
|
| 3 |
size 1135701541
|