
Commit
•
8f2fba8
1
Parent(s):
49a3424
upload
Browse files- README.md +38 -0
- adapter_config.json +28 -0
- adapter_model.bin +3 -0
- all_results.json +7 -0
- special_tokens_map.json +24 -0
- sqlctx-r16.punica.pt +3 -0
- tokenizer.json +0 -0
- tokenizer.model +3 -0
- tokenizer_config.json +40 -0
- train_results.json +7 -0
- trainer_log.jsonl +0 -0
- trainer_state.json +0 -0
- training_args.bin +3 -0
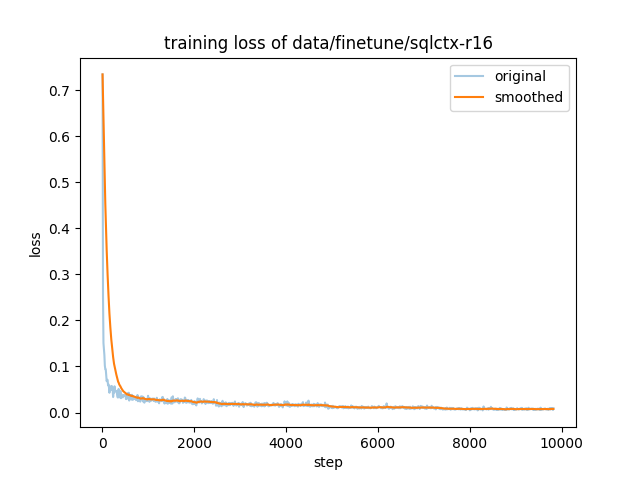
- training_loss.png +0 -0
README.md
CHANGED
|
@@ -1,3 +1,41 @@
|
|
| 1 |
---
|
| 2 |
license: apache-2.0
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 3 |
---
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
---
|
| 2 |
license: apache-2.0
|
| 3 |
+
base_model: meta-llama/Llama-2-7b-hf
|
| 4 |
+
datasets:
|
| 5 |
+
- b-mc2/sql-create-context
|
| 6 |
+
language:
|
| 7 |
+
- en
|
| 8 |
+
pipeline_tag: text2text-generation
|
| 9 |
+
tags:
|
| 10 |
+
- punica
|
| 11 |
+
- llama-factory
|
| 12 |
+
- lora
|
| 13 |
+
- generated_from_trainer
|
| 14 |
---
|
| 15 |
+
|
| 16 |
+
* Base Model: [Llama-2-7b-hf](https://huggingface.co/meta-llama/Llama-2-7b-hf)
|
| 17 |
+
* LoRA target: `q_proj,k_proj,v_proj,o_proj,gate_proj,up_proj,down_proj`
|
| 18 |
+
* LoRA rank: 16
|
| 19 |
+
|
| 20 |
+
See <https://github.com/punica-ai/punica/tree/master/examples/finetune>
|
| 21 |
+
|
| 22 |
+
|
| 23 |
+
### Training hyperparameters
|
| 24 |
+
|
| 25 |
+
The following hyperparameters were used during training:
|
| 26 |
+
- learning_rate: 5e-05
|
| 27 |
+
- train_batch_size: 32
|
| 28 |
+
- eval_batch_size: 8
|
| 29 |
+
- seed: 42
|
| 30 |
+
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
|
| 31 |
+
- lr_scheduler_type: cosine
|
| 32 |
+
- num_epochs: 4.0
|
| 33 |
+
|
| 34 |
+
|
| 35 |
+
|
| 36 |
+
### Framework versions
|
| 37 |
+
|
| 38 |
+
- Transformers 4.34.1
|
| 39 |
+
- Pytorch 2.2.0.dev20230911+cu121
|
| 40 |
+
- Datasets 2.14.4
|
| 41 |
+
- Tokenizers 0.14.1
|
adapter_config.json
ADDED
|
@@ -0,0 +1,28 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"alpha_pattern": {},
|
| 3 |
+
"auto_mapping": null,
|
| 4 |
+
"base_model_name_or_path": "meta-llama/Llama-2-7b-hf",
|
| 5 |
+
"bias": "none",
|
| 6 |
+
"fan_in_fan_out": false,
|
| 7 |
+
"inference_mode": true,
|
| 8 |
+
"init_lora_weights": true,
|
| 9 |
+
"layers_pattern": null,
|
| 10 |
+
"layers_to_transform": null,
|
| 11 |
+
"lora_alpha": 16.0,
|
| 12 |
+
"lora_dropout": 0.1,
|
| 13 |
+
"modules_to_save": null,
|
| 14 |
+
"peft_type": "LORA",
|
| 15 |
+
"r": 16,
|
| 16 |
+
"rank_pattern": {},
|
| 17 |
+
"revision": null,
|
| 18 |
+
"target_modules": [
|
| 19 |
+
"gate_proj",
|
| 20 |
+
"up_proj",
|
| 21 |
+
"down_proj",
|
| 22 |
+
"o_proj",
|
| 23 |
+
"v_proj",
|
| 24 |
+
"k_proj",
|
| 25 |
+
"q_proj"
|
| 26 |
+
],
|
| 27 |
+
"task_type": "CAUSAL_LM"
|
| 28 |
+
}
|
adapter_model.bin
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:e7c6b1ffd5d9dc567b0014a251fbac14d83d9d01b7d1fb1322a0c9627ee4f139
|
| 3 |
+
size 160069834
|
all_results.json
ADDED
|
@@ -0,0 +1,7 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"epoch": 4.0,
|
| 3 |
+
"train_loss": 0.01796033810001285,
|
| 4 |
+
"train_runtime": 18572.7384,
|
| 5 |
+
"train_samples_per_second": 16.923,
|
| 6 |
+
"train_steps_per_second": 0.529
|
| 7 |
+
}
|
special_tokens_map.json
ADDED
|
@@ -0,0 +1,24 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"bos_token": {
|
| 3 |
+
"content": "<s>",
|
| 4 |
+
"lstrip": false,
|
| 5 |
+
"normalized": false,
|
| 6 |
+
"rstrip": false,
|
| 7 |
+
"single_word": false
|
| 8 |
+
},
|
| 9 |
+
"eos_token": {
|
| 10 |
+
"content": "</s>",
|
| 11 |
+
"lstrip": false,
|
| 12 |
+
"normalized": false,
|
| 13 |
+
"rstrip": false,
|
| 14 |
+
"single_word": false
|
| 15 |
+
},
|
| 16 |
+
"pad_token": "</s>",
|
| 17 |
+
"unk_token": {
|
| 18 |
+
"content": "<unk>",
|
| 19 |
+
"lstrip": false,
|
| 20 |
+
"normalized": false,
|
| 21 |
+
"rstrip": false,
|
| 22 |
+
"single_word": false
|
| 23 |
+
}
|
| 24 |
+
}
|
sqlctx-r16.punica.pt
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:87e321a0ff1fc10a4244d9549357eb40e0729fe8c1cbfb7f5dcff1288a43ee93
|
| 3 |
+
size 159912672
|
tokenizer.json
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|
tokenizer.model
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:9e556afd44213b6bd1be2b850ebbbd98f5481437a8021afaf58ee7fb1818d347
|
| 3 |
+
size 499723
|
tokenizer_config.json
ADDED
|
@@ -0,0 +1,40 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"added_tokens_decoder": {
|
| 3 |
+
"0": {
|
| 4 |
+
"content": "<unk>",
|
| 5 |
+
"lstrip": false,
|
| 6 |
+
"normalized": false,
|
| 7 |
+
"rstrip": false,
|
| 8 |
+
"single_word": false,
|
| 9 |
+
"special": true
|
| 10 |
+
},
|
| 11 |
+
"1": {
|
| 12 |
+
"content": "<s>",
|
| 13 |
+
"lstrip": false,
|
| 14 |
+
"normalized": false,
|
| 15 |
+
"rstrip": false,
|
| 16 |
+
"single_word": false,
|
| 17 |
+
"special": true
|
| 18 |
+
},
|
| 19 |
+
"2": {
|
| 20 |
+
"content": "</s>",
|
| 21 |
+
"lstrip": false,
|
| 22 |
+
"normalized": false,
|
| 23 |
+
"rstrip": false,
|
| 24 |
+
"single_word": false,
|
| 25 |
+
"special": true
|
| 26 |
+
}
|
| 27 |
+
},
|
| 28 |
+
"bos_token": "<s>",
|
| 29 |
+
"clean_up_tokenization_spaces": false,
|
| 30 |
+
"eos_token": "</s>",
|
| 31 |
+
"legacy": false,
|
| 32 |
+
"model_max_length": 1000000000000000019884624838656,
|
| 33 |
+
"pad_token": "</s>",
|
| 34 |
+
"padding_side": "right",
|
| 35 |
+
"sp_model_kwargs": {},
|
| 36 |
+
"split_special_tokens": false,
|
| 37 |
+
"tokenizer_class": "LlamaTokenizer",
|
| 38 |
+
"unk_token": "<unk>",
|
| 39 |
+
"use_default_system_prompt": true
|
| 40 |
+
}
|
train_results.json
ADDED
|
@@ -0,0 +1,7 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"epoch": 4.0,
|
| 3 |
+
"train_loss": 0.01796033810001285,
|
| 4 |
+
"train_runtime": 18572.7384,
|
| 5 |
+
"train_samples_per_second": 16.923,
|
| 6 |
+
"train_steps_per_second": 0.529
|
| 7 |
+
}
|
trainer_log.jsonl
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|
trainer_state.json
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|
training_args.bin
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:3848f4caaf8f90ffa05a58fb5d63cf874b8aa053b5e44103a147f7f6a660c2de
|
| 3 |
+
size 4664
|
training_loss.png
ADDED
|